

ในช่วงแรกๆ ของการผลิตอัตโนมัติ เครื่องจักรทำงานแค่ตามคำสั่งที่ตายตัว เหมือนคนตาบอดที่เดินตามเส้นทางที่จำได้แม่นยำ แต่ไม่สามารถรับมือกับสถานการณ์ที่เปลี่ยนแปลงได้ การเปิดตาให้เครื่องจักรครั้งแรกเริ่มต้นในช่วงปี 1960 เมื่อนักวิจัยพยายามให้คอมพิวเตอร์สามารถแยกแยะรูปร่างง่ายๆ ได้ แต่เทคโนโลยีในยุคนั้นยังจำกัดมาก ต้องใช้คนเขียนกฎเกณฑ์และขั้นตอนการทำงานทุกอย่างแบบละเอียดมาก
ความก้าวหน้าครั้งสำคัญเกิดขึ้นในช่วงปี 1970 เมื่อมีการพัฒนาอัลกอริทึมประมวลผลภาพดิจิทัลครั้งแรก และต่อมาในปี 1977 การวิเคราะห์ blob ได้ถือกำเนิดขึ้นเป็นส่วนหนึ่งของ SRI Algorithm ซึ่งยังคงเป็นองค์ประกอบสำคัญของซอฟต์แวร์ machine vision จนถึงปัจจุบัน หลังจากนั้นในปี 1985 การพัฒนา morphology ได้เข้ามาเพิ่มความสามารถในการวิเคราะห์รูปร่างและโครงสร้างของวัตถุ
วันนี้ตลาดของ Vision Technology กำลังเติบโตอย่างรวดเร็ว โดยคาดการณ์ว่าจะมีมูลค่าถึง 9.3 พันล้านดอลลาร์ภายในปี 2028 ด้วยอัตราการเติบโตเฉลี่ย 6.4% ต่อปี ส่วนตลาด Computer Vision โดยรวมก็คาดว่าจะโตขึ้นจาก 31.83 พันล้านดอลลาร์ในปี 2025 เป็น 175.72 พันล้านดอลลาร์ในปี 2032
ด้วยอัตราการเติบโต 27.6% ต่อปี ตัวเลขเหล่านี้สะท้อนให้เห็นถึงความสำคัญและศักยภาพอันมหาศาลของเทคโนโลยีนี้ในโลกอุตสาหกรรมสมัยใหม่
ดวงตาเทียมและสมองกล
หากเปรียบเทียบระบบ Vision Technology กับการทำงานของตาและสมองมนุษย์ ส่วนประกอบฮาร์ดแวร์ก็เปรียบเสมือนดวงตาที่ทำหน้าที่รับแสงและแปลงเป็นสัญญาณ ส่วนซอฟต์แวร์ประมวลผลภาพก็เหมือนสมองที่ตีความหมายและตัดสินใจ
เซนเซอร์ภาพที่เป็นหัวใจสำคัญมีสองประเภทหลัก คือ CCD (Charge-Coupled Device) และ CMOS (Complementary Metal-Oxide Semiconductor) เซนเซอร์ CCD ทำงานแบบ bucket brigade โดยถ่ายโอนประจุไฟฟ้าที่เกิดจากการกระทบของโฟตอนจากพิกเซลหนึ่งไปยังอีกพิกเซลหนึ่ง
ทำให้ได้ความสม่ำเสมอสูงระหว่างพิกเซล แต่มีข้อจำกัดเรื่องความเร็ว ในขณะที่เซนเซอร์ CMOS แปลงประจุเป็นแรงดันไฟฟ้าที่พิกเซลแต่ละตัวโดยตรง จึงมีความเร็วสูงและประหยัดพลังงานกว่า
ที่น่าสนใจคือเซนเซอร์เหล่านี้สามารถตรวจจับแสงในช่วงความยาวคลื่น 350-1050 นาโนเมตร ซึ่งครอบคลุมทั้งแสงที่มองเห็นได้และแสงอินฟราเรดใกล้ การออกแบบเซนเซอร์ต้องพิจารณาถึงขนาดพิกเซล ความละเอียด และอัตราส่วนกว้าง-ยาวให้เหมาะสมกับการใช้งานแต่ละประเภท
นวัตกรรมล่าสุดอย่างเทคโนโลยี Nanoprism ของ Samsung ใช้ Meta-Photonics เพื่อเพิ่มความไว โดยใช้โครงสร้างระดับนาโนเมตรที่สามารถนำแสงที่จะสูญหายไปยังพิกเซลข้างเคียงผ่านการหักเหและการกระจายของแสง
ระบบแสงสว่างถือเป็นองค์ประกอบที่มักถูกมองข้าม แต่จริงๆ แล้วเป็นตัวกำหนดความสำเร็จมากที่สุด การให้แสงที่ดีจะช่วยเพิ่มความเข้มข้นของลักษณะเด่นที่ต้องการตรวจจับ และลดสัญญาณรบกวนในส่วนอื่นๆ มีหลายรูปแบบเช่น Ring Lights สำหรับให้แสงสม่ำเสมอรอบๆ วัตถุ Bar Lights สำหรับให้แสงเป็นเส้นตรง
Back Lights สำหรับสร้าง silhouette และ Dome Lights สำหรับให้แสงแบบกระจาย การเลือกใช้แต่ละประเภทต้องพิจารณาคุณสมบัติของพื้นผิววัตถุ เช่น ความเรียบ ความโค้ง การสะท้อนแสง และสีของวัตถุ
จากพิกเซลสู่ความเข้าใจ
เมื่อแสงกระทบกับเซนเซอร์ สิ่งที่เกิดขึ้นคือการเปลี่ยนแปลงจากโลกกายภาพสู่โลกดิจิทัล โฟตอนแต่ละตัวจะถูกแปลงเป็นสัญญาณไฟฟ้า จากนั้นผ่านการแปลงจากสัญญาณแอนาล็อกเป็นสัญญาณดิจิทัล(Analog-to-Digital Conversion)
เพื่อให้เป็นข้อมูลตัวเลขที่คอมพิวเตอร์สามารถประมวลผลได้ ภาพดิจิทัลจะถูกแสดงในรูปแบบของเมทริกซ์หรือ array หลายมิติ โดยแต่ละองค์ประกอบจะแทนค่าความเข้มข้นของแสงหรือสีของพิกเซลแต่ละตัว การประมวลผลภาพเริ่มจากเทคนิคระดับพื้นฐานอย่างเช่น
- การปรับปรุงความเข้มข้น (Contrast Enhancement)
- การลดสัญญาณรบกวน (Noise Reduction)
- การปรับสมดุลสี
จากนั้นจะดำเนินไปสู่เทคนิคระดับกลาง เช่น การแปลงเป็นภาพไบนารี (Binarization) และการบีบอัดข้อมูล และสุดท้ายจะเป็นเทคนิคระดับสูง เช่น การตรวจจับขอบ การแบ่งส่วนภาพ และการจดจำวัตถุ
การตรวจจับขอบ (Edge Detection) เป็นหนึ่งในเทคนิคพื้นฐานที่สำคัญที่สุด มีอัลกอริทึมหลากหลายแบบ เช่น Sobel Operator ที่วัดการเปลี่ยนแปลงของความเข้มข้นภาพ Canny Edge Detector ที่เป็นอัลกอริทึมหลายขั้นตอนที่ซับซ้อน และ Laplacian of Gaussian (LoG)
ที่ผสมผสานระหว่างการลดสัญญาณรบกวนและการตรวจจับขอบ การทำงานของ Sobel Filter ใช้ convolution kernels ในการประมาณ image gradients เพื่อเน้นพื้นที่ที่มีการเปลี่ยนแปลงความเข้มแสงอย่างรวดเร็ว
การตรวจจับลักษณะเด่น (Feature Detection) ใช้เทคนิคที่ซับซ้อนกว่า เช่น Scale-Invariant Feature Transform (SIFT) ที่สามารถตรวจจับจุดสำคัญในภาพที่ไม่เปลี่ยนแปลงตามขนาดและการหมุน8 SIFT ทำงานผ่านขั้นตอนหลักสี่ขั้นตอน คือ การตรวจจับ extrema ในพื้นที่ scale-space การ localization ที่แม่นยำของจุดสำคัญ การกำหนดทิศทางที่สม่ำเสมอ และการสร้าง descriptor ที่โดดเด่นตาม gradient ของภาพท้องถิ่น
Histogram of Oriented Gradients (HOG) เป็นอีกเทคนิคที่สำคัญ ซึ่งจับข้อมูลรูปร่างท้องถิ่นโดยการวิเคราะห์รูปแบบ gradient ทั่วทั้งภาพ กระบวนการเริ่มต้นด้วยการคำนวณ gradients ทั่วทั้งภาพ จากนั้นภาพจะถูกแบ่งออกเป็นเซลล์เล็กๆ และสำหรับแต่ละเซลล์จะสร้างฮิสโตแกรมของการวางแนว gradient เพื่อสรุปโครงสร้างท้องถิ่น
หัวใจแห่งปัญญาประดิษฐ์
หากการประมวลผลภาพแบบดั้งเดิมเปรียบเสมือนการใช้กฎเกณฑ์ที่มนุษย์กำหนดไว้ Convolutional Neural Networks (CNNs) ก็เหมือนการสอนเครื่องจักรให้เรียนรู้และคิดเองได้
CNNs เป็นประเภทของ neural network ที่ออกแบบมาเป็นพิเศษสำหรับการประมวลผลข้อมูลที่มีโครงสร้างแบบตาราง เช่น ภาพ โดยใช้การดำเนินการ convolution เพื่อสกัดลักษณะเด่นจากข้อมูลอินพุต
CNNs ประกอบด้วยหลายชั้น (layers) ที่ทำงานร่วมกัน ชั้น convolution เป็นหัวใจสำคัญที่ใช้ filters หรือ kernels ที่เป็นเมทริกซ์ขนาดเล็กในการสแกนข้อมูลอินพุต การทำงานของ convolution
หรือก็คือการคำนวณ dot product ระหว่าง filter และบริเวณของภาพที่ filter กำลังดู ผลลัพธ์จะเป็น feature map ที่แสดงถึงการมีอยู่ของลักษณะเฉพาะในตำแหน่งต่างๆ ของภาพ
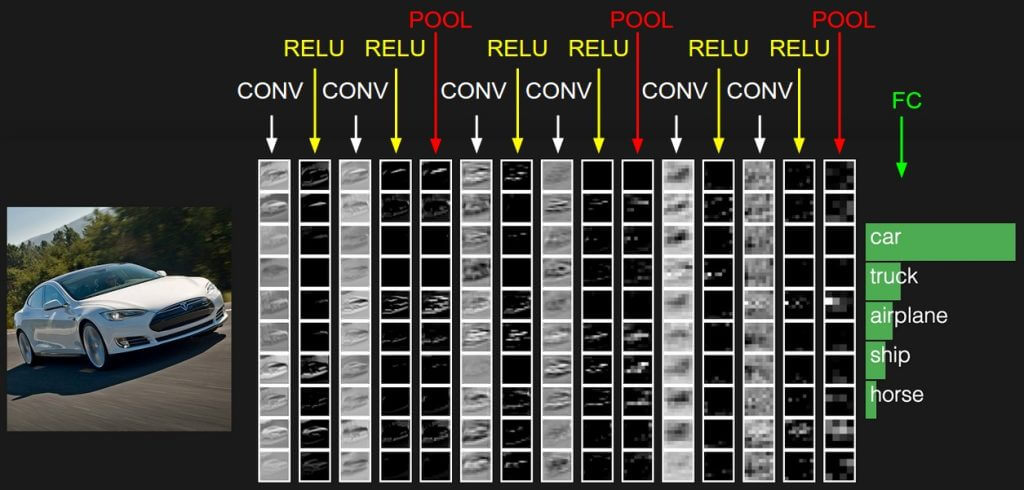
ขอบคุณรูปจาก : CS231n Deep Learning
ชั้น pooling ทำหน้าที่ลดขนาดของ feature maps โดยการสรุปข้อมูลในบริเวณเล็กๆ เช่น การใช้ max pooling ที่เลือกค่าสูงสุดในแต่ละพื้นที่ หรือ average pooling ที่คำนวณค่าเฉลี่ย การทำงานนี้ช่วยลดจำนวนพารามิเตอร์และการคำนวณ
ขณะเดียวกันก็ช่วยให้โมเดลมีความทนทานต่อการเปลี่ยนแปลงตำแหน่งของวัตถุในภาพ ที่น่าสนใจคือแนวคิด max pooling ถูกนำเสนอครั้งแรกในปี 1990
การเรียนรู้ของ CNNs เกิดขึ้นผ่านกระบวนการ backpropagation ที่ปรับค่า weights ของ filters ให้เหมาะสมกับงานที่ต้องการ ในชั้นแรกๆ CNNs จะเรียนรู้การตรวจจับลักษณะพื้นฐาน เช่น ขอบและสี ในชั้นกลางจะรวมลักษณะเหล่านี้เข้าด้วยกันเป็นรูปแบบและรูปร่าง และในชั้นลึกจะจดจำวัตถุที่ซับซ้อนและทำความเข้าใจฉาก
ประสิทธิภาพของ CNNs ในงาน computer vision นั้นน่าสนใจมาก เพราะในปี 2012 AlexNet ได้ลดอัตราผิดพลาดลงมาต่ำกว่า 5% ด้วยการใช้ deep learning และในปี 2015 CNN ที่มีหลายชั้นสามารถตรวจจับใบหน้าจากมุมต่างๆ ได้
รวมถึงใบหน้าที่กลับหัว และแม้ว่าจะถูกบดบังบางส่วนก็ตาม โดยเครือข่ายถูกฝึกด้วยฐานข้อมูลที่มีใบหน้า 200,000 ภาพและภาพที่ไม่มีใบหน้าอีก 20 ล้านภาพ
เมื่อเครื่องจักรรู้จักเรียนรู้ได้ด้วยตัวเอง
สิ่งที่ทำให้ Vision Technology สมัยใหม่แตกต่างจากระบบเก่าๆ คือความสามารถในการเรียนรู้และปรับปรุงตัวเองได้ การเตรียมข้อมูลการฝึกอบรมเป็นขั้นตอนที่สำคัญมาก
คุณภาพของชุดข้อมูลส่งผลโดยตรงต่อประสิทธิภาพและความสามารถในการทำงานของโมเดล การฝึกโมเดลต้องใช้ภาพที่มีป้ายกำกับตั้งแต่ 10,000 ถึง 10 ล้านภาพ ขึ้นอยู่กับความซับซ้อนของงาน
ข้อมูลต้องมีความหลากหลาย มีการ annotation ที่แม่นยำ ครอบคลุมสภาพแวดล้อมที่ระบบจะทำงาน มีความสมดุลระหว่างคลาสต่างๆ และมีคุณภาพภาพ/วิดีโอที่ดี การทำ data annotation หรือการติดป้ายข้อมูลต้องมีแนวทางที่ชัดเจน
โดยผู้ทำ annotation ที่มีคุณภาพ เครื่องมือที่เหมาะสม และการควบคุมคุณภาพอย่างสม่ำเสมอ
การเสริมข้อมูล (Data Augmentation) เป็นเทคนิคสำคัญที่ช่วยเพิ่มขนาดของชุดข้อมูล โดยการหมุน การพลิก การครอบตัดภาพ การเพิ่มสัญญาณรบกวน และการปรับสีหรือความสว่าง
เป้าหมายคือลด overfitting ซึ่งเกิดขึ้นเมื่อโมเดลเรียนรู้ข้อมูลการฝึกอบรมอย่างใกล้ชิดเกินไป ทำให้ทำนายข้อมูลใหม่ได้ไม่ดี
วิธีการฝึกอบรมมีหลากหลายรูปแบบ ได้แก่
- Supervised Learning ใช้ข้อมูลที่มีป้ายกำกับ เหมาะสำหรับการจำแนกประเภทและการตรวจจับวัตถุ
- Unsupervised Learning ค้นหารูปแบบในข้อมูลที่ไม่มีป้ายกำกับ และ
- Semi-supervised Learning ผสมผสานข้อมูลที่มีป้ายกำกับเล็กน้อยกับข้อมูลที่ไม่มีป้ายกำกับจำนวนมาก
การประมวลผลแบบเรียลไทม์ด้วยความเร็วแสง
ในสภาพแวดล้อมการผลิตจริง ระบบ Vision Technology ไม่สามารถใช้เวลาหลายนาทีในการคิดได้ เพราะสายการผลิตเคลื่อนที่ไม่หยุด การประมวลผลภาพแบบเรียลไทม์จึงเป็นความท้าทายหลัก ระบบต้องประมวลผลข้อมูลภาพจำนวนมหาศาลภายในเวลาที่จำกัดเพื่อให้สามารถตอบสนองได้ทันท่วงที
อัตราเฟรมของกล้อง (frame rate) เป็นปัจจัยสำคัญที่กำหนดจำนวนภาพต่อวินาทีที่สามารถจับได้ เมื่อภาพถูกจับแล้ว ระบบ intelligence จะเริ่มวิเคราะห์ภาพ ความสามารถในการประมวลผลยังขึ้นอยู่กับความซับซ้อนของระบบและการใช้งาน เช่น
- การใช้ machine vision สำหรับการวัดวัตถุ
- การตรวจสอบข้อบกพร่องที่ต้องเปรียบเทียบภาพที่จับได้กับฐานข้อมูลของภาพหลายภาพ
การเพิ่มประสิทธิภาพการประมวลผลเรียลไทม์ใช้เทคนิคหลายอย่าง เช่น การใช้ pipeline processing ที่แต่ละขั้นตอนในการประมวลผลทำหน้าที่เฉพาะ และข้อมูลไหลผ่านแต่ละขั้นตอนแบบต่อเนื่องและขนานกัน
วิธีนี้ช่วยให้มีการประมวลผลที่มีความแน่นอนสูงและเวลาตอบสนองที่ต่ำ
พลังแห่งฮาร์ดแวร์ CPU vs GPU vs FPGA
การเลือกใช้ฮาร์ดแวร์ที่เหมาะสมเป็นสิ่งสำคัญสำหรับประสิทธิภาพของระบบ Vision Technology ซึ่ง CPU เป็นหัวใจของคอมพิวเตอร์แบบดั้งเดิม มีความยืดหยุ่นสูงและเหมาะสำหรับงานที่ต้องการการควบคุมที่ซับซ้อน แต่มีข้อจำกัดในด้านความเร็วการประมวลผลแบบขนาน
GPU ถูกออกแบบมาเพื่อการประมวลผลแบบขนานที่มีประสิทธิภาพสูง มีสถาปัตยกรรมที่ประกอบด้วยหลายพันคอร์และเหมาะสำหรับการคำนวณเกี่ยวกับพิกเซล GPU มีประสิทธิภาพสูงในงาน deep learning และมีหน่วยความจำขนาดใหญ่สำหรับการจัดการชุดข้อมูลขนาดใหญ่
FPGA ใช้วงจรที่สามารถโปรแกรมได้เพื่อรันโปรแกรมที่กำหนดเองในระดับตรรกะที่ต่ำ ใช้พลังงานน้อยกว่า CPU หรือ GPU ไม่ต้องการค่าใช้จ่ายของระบบปฏิบัติการ มีเวลาตอบสนองต่ำมาก และสามารถเร่งกระบวนการหลายส่วนของ computer vision pipeline ได้พร้อมกันในขณะที่ GPU สามารถเร่งได้เพียงส่วนเดียว
ผลการทดสอบแสดงให้เห็นว่า FPGA มีประสิทธิภาพเหนือกว่า GPU ในด้านเวลาตอบสนอง การใช้พลังงาน และการใช้ทรัพยากรสำหรับภาพขนาด 512×512 พิกเซล แต่ GPU จัดการกับการขยายความละเอียดได้ดีกว่า FPGA การใช้ hybrid approaches ที่ผสมผสาน traditional computer vision และ deep learning สามารถให้ประโยชน์ของทั้งสองวิธี
เรื่องเล่าความสำเร็จจากโรงงาน
ให้เราดูตัวอย่างจากโลกจริงที่แสดงให้เห็นว่า Vision Technology ช่วยเปลี่ยนแปลงอุตสาหกรรมได้อย่างไร บริษัทผลิตเครื่องใช้ไฟฟ้าแห่งหนึ่งได้นำระบบ AI vision มาใช้ในสายการผลิตที่มีอัตราข้อบกพร่องที่สูง
ระบบสามารถตรวจสอบงานแบบเรียลไทม์และพบปัญหาที่ผู้ปฏิบัติงานที่ทำการตรวจสอบด้วยตาเปล่าพลาด ส่งผลให้สามารถลดข้อบกพร่องได้ถึง 30% ในช่วง 6 เดือนแรก และประหยัดค่าใช้จ่ายในการแก้ไขและเศษซากเหลือทิ้งได้ถึง 500,000 ดอลลาร์
การนำระบบ AI vision มาใช้ในการติดตามกระบวนการประกอบในวงการ Automotive ทำให้สามารถจับข้อผิดพลาดได้ที่แต่ละสถานี ปรับปรุงการฝึกอบรมพนักงาน และผลิตชิ้นส่วนรถยนต์ที่มีคุณภาพสูงขึ้น ส่งผลให้อัตราการขอเครมชิ้นส่วนที่เสียหายลดลง 60%
บริษัทรีไซเคิลพลาสติกเกรดอาหารได้ใช้ระบบ AI vision ที่ฝึกด้วยภาพหลายพันภาพในการตรวจสอบเศษพลาสติกจากขวดที่บดแล้ว เพื่อให้แน่ใจว่าบริสุทธิ์พอสำหรับการนำกลับมาใช้ใหม่ ระบบ AI ทำงานตรวจสอบอนุภาคแปลกปลอมได้ดีกว่าคนงานมากมาย
นี่คือตัวอย่างที่แสดงให้เห็นว่า AI สามารถแก้ปัญหาที่เป็นไปไม่ได้ด้วยการประมวลผลภาพแบบดั้งเดิม เช่น การเรียงลำดับวัสดุที่ไม่สม่ำเสมอ
บริษัท hot sauce maker สามารถตรวจสอบการติดฉลากได้ด้วยอัตราเกิน 1,000 ชิ้นต่อนาที ส่วนในอุตสาหกรรมยานยนต์ FANUC ได้พัฒนาซอฟต์แวร์ที่เรียกว่า ZDT (Zero Down Time) ที่เก็บภาพจากกล้องที่ติดอยู่กับหุ่นยนต์
ภาพและข้อมูลจะถูกส่งไปยัง cloud เพื่อการประมวลผลและช่วยระบุปัญหาที่อาจจะเกิดขึ้นก่อนที่จะเกิดขึ้นจริง ในระหว่างการทดลองใช้งาน 18 เดือน ระบบถูกนำไปใช้กับหุ่นยนต์ 7,000 ตัวใน 38 โรงงานยานยนต์ทั่ว 6 ทวีป และสามารถตรวจจับและป้องกันการเสียหายของชิ้นส่วนได้ 72 ครั้ง
นวัตกรรมนี้กำลังเปลี่ยนโลก
เทคโนโลยี Vision ไม่หยุดพัฒนา ในปี 2025 เราจะเห็นการรวมตัวของ AI และ IoT มากขึ้น ทำให้เกิดระบบ Automation ที่ฉลาดและเชื่อมต่อกันมากขึ้น ระบบเหล่านี้สามารถแบ่งปันข้อมูลและเรียนรู้จากประสบการณ์ร่วมกัน ทำให้เกิดการปรับปรุงประสิทธิภาพอย่างต่อเนื่องทั่วทั้งเครือข่ายการผลิต
Edge computing และ intelligent sensors กำลังเปลี่ยนแปลงการประมวลผลข้อมูลโดยการนำความฉลาดไปยังจุดที่ข้อมูลถูกสร้าง ลดการ latency และการพึ่งพาการเชื่อมต่อกับ cloud ความก้าวหน้าในด้าน edge computing สำหรับระบบ vision
คาดว่าจะช่วยในการประมวลผลข้อมูลภาพแบบเรียลไทม์โดยตรงบนอุปกรณ์ ซึ่งมีความสำคัญสำหรับการใช้งานเช่น รถยนต์ไร้คนขับ โดรน และการควบคุมคุณภาพแบบเรียลไทม์ในโรงงาน
การพัฒนาอัลกอริทึมใหม่ๆ เช่น Transformer-based models ที่ใช้ self-attention mechanism กำลังแสดงให้เห็นถึงประสิทธิภาพที่โดดเด่นในงาน object detection
การใช้ Vision Transformers (ViT) และ DETR (Detection Transformer) ช่วยลดความซับซ้อนของ pipeline โดยการขจัด hand-crafted processes เช่น Non-maximum suppression (NMS)
เทคนิค self-supervised learning และ few-shot learning กำลังช่วยลดความต้องการข้อมูลการฝึกอบรมที่มีป้ายกำกับ ทำให้สามารถพัฒนาระบบ vision ได้รวดเร็วและประหยัดต้นทุนมากขึ้น
การใช้ Reinforcement Learning from Human Feedback (RLHF) ช่วยปรับปรุงประสิทธิภาพของโมเดลโดยใช้ feedback จากมนุษย์
สำหรับเทคโนโลยีเซนเซอร์ความก้าวหน้าในด้าน shortwave infrared (SWIR) sensing กำลังก้าวหน้าอย่างมาก เซนเซอร์ SWIR แบบ hybrid ของ Sony และการพาณิชย์ของเซนเซอร์ quantum dot ของ SWIR Vision Systems ได้ช่วยลดต้นทุนของการถ่ายภาพ SWIR และให้การตอบสนองในสเปกตรัมกว้างประมาณ 300-2,000 นาโนเมตร
การรวมระหว่างแสง LED และตัวกรองพิเศษสามารถเปิดโอกาสใหม่สำหรับการถ่ายภาพหลายสเปกตรัมในระบบกล้องเดียวและในระดับราคาที่ไม่เคยเป็นไปได้มาก่อน
การเปิดตาครั้งยิ่งใหญ่ของโลกอุตสาหกรรม
Vision Technology ใน Automation ไม่ได้เป็นแค่เครื่องมือที่ช่วยให้เครื่องจักร “มองเห็น” แต่เป็นการปฏิวัติครั้งใหญ่ที่เปลี่ยนแปลงวิธีที่เราผลิต ตรวจสอบ และจัดการกระบวนการอุตสาหกรรม จากการเริ่มต้นที่เรียบง่ายในช่วงทศวรรษที่ 1960 ไปจนถึงระบบ AI ที่ซับซ้อนในปัจจุบัน
เทคโนโลยีนี้ได้พิสูจน์แล้วว่าสามารถสร้างความแตกต่างที่สำคัญในด้านคุณภาพ ประสิทธิภาพ และความปลอดภัย
ความสามารถในการ ‘รู้’ ว่ากำลังมองเห็นอะไรนั้นมาจากการผสมผสานที่ซับซ้อนระหว่างฮาร์ดแวร์ที่ทันสมัย อัลกอริทึมที่ชาญฉลาด และกระบวนการเรียนรู้ที่ไม่หยุดนิ่ง จากเซนเซอร์ที่แปลงแสงเป็นข้อมูลดิจิทัล
ผ่านการประมวลผลภาพที่ซับซ้อน ไปจนถึง Convolutional Neural Networks ที่เรียนรู้รูปแบบและตัดสินใจได้เหมือนสมองมนุษย์ แต่มีความแม่นยำและความสม่ำเสมอที่เหนือกว่า
แม้จะมีความท้าทายในด้านการประมวลผลแบบเรียลไทม์ ความต้องการข้อมูลการฝึกอบรมจำนวนมาก และความซับซ้อนของการตั้งค่าระบบ แต่ประโยชน์ที่ได้รับก็คุ้มค่าอย่างมาก ตั้งแต่การประหยัดต้นทุนหลายแสนดอลลาร์ ไปจนถึงการป้องกันอุบัติเหตุและการปรับปรุงคุณภาพผลิตภัณฑ์
อนาคตของ Vision Technology ใน Automation นั้นเต็มไปด้วยความเป็นไปได้ การรวมตัวกับ AI และ IoT การพัฒนา edge computing และอัลกอริทึมใหม่ๆ รวมถึงเซนเซอร์ที่ก้าวหน้า ล้วนชี้ไปที่โลกที่เครื่องจักรไม่เพียงแต่มองเห็น แต่เข้าใจและตัดสินใจได้อย่างชาญฉลาดกว่าที่คิดไว้
สำหรับผู้ที่กำลังพิจารณาการนำเทคโนโลยีนี้มาใช้ หรือเพียงแค่อยากเข้าใจความมหัศจรรย์เบื้องหลังการที่เครื่องจักรสามารถ ‘เห็น’ และ ‘เข้าใจ’ ได้ เรื่องราวที่เล่ามาทั้งหมดนี้แสดงให้เห็นว่า
Vision Technology ไม่ได้เป็นแค่จินตนาการ แต่เป็นผลผลิตของการพัฒนาทางวิทยาศาสตร์และเทคโนโลยีที่ต่อเนื่องมานานหลายทศวรรษ และยังคงมีศักยภาพที่จะเปลี่ยนแปลงโลกของเราให้ดีขึ้นต่อไปในอนาคต
แหล่งข้อมูล
opencv.org , qualitymag.com , automate.org , fortunebusinessinsights.com , sciotex.com , milvus.io , geeksforgeeks.org , al-khwarizmy.com , unitxlabs.com , portwell.tw , viso.ai , devteam.space







